Understanding AI Project Cycle
The AI Project Cycle is a step-by-step framework used to design and develop an Artificial Intelligence (AI) project. It ensures that the problem is addressed systematically and the final solution is effective.
Here are the five key stages:
1. Problem Scoping
This is the starting point where you define the goal of your project. You identify a problem that needs to be solved and decide how AI can help. To do this effectively, we often use the 4Ws Problem Canvas:
- Who: Who is facing the problem?
- What: What is the nature of the problem?
- Where: Where does the problem arise (context/location)?
- Why: Why is it important to solve it?
2. Data Acquisition
AI models need data to learn. In this stage, you collect relevant data from various sources such as surveys, sensors, web scraping, or datasets. The quality and quantity of the data you collect directly determine how “smart” your AI will be.
3. Data Exploration
Once the data is collected, it needs to be organized and understood. In this stage, you:
- Clean the data (remove errors or duplicates).
- Visualize the data using charts or graphs to find patterns and trends.
- Check if the data is sufficient to meet the project’s goals.
4. Modelling
This is the stage where the actual AI “brain” is built. You select a suitable algorithm and train it using the data you have prepared. AI models generally fall into three following categories:
- Regression: Predicting numerical values (e.g., price of a house).
- Classification: Grouping data into categories (e.g., Spam vs. Not Spam).
- Clustering: Finding hidden patterns and grouping similar items together.
5. Evaluation
After the model is trained, it must be tested with new data (data it hasn’t seen before) to check its accuracy. If the model provides incorrect results, you may need to go back to previous stages—like collecting better data or choosing a different algorithm—to improve it.
6. Deployment
Finally, after evaluation, the deployment stage is crucial for ensuring the successful
integration and operation of AI solutions in real-world environments, enabling them to deliver
value and impact to users and stakeholders.
Modelling
AI Modelling refers to developing algorithms, also called models which can be trained to get
intelligent outputs. That is, writing codes to make a machine artificially intelligent.
Types of AI Models: Generally, AI models can be classified as follows:
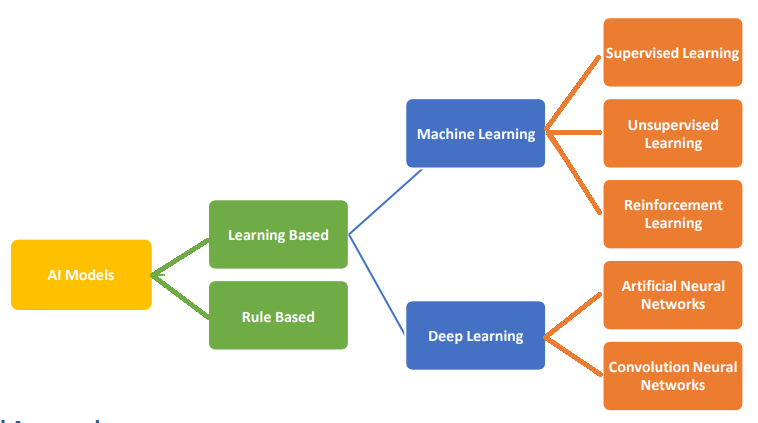
1. Rule Based Approach
Rule Based Approach refers to the AI modelling where the relationship or patterns in data are defined by the developer. The machine follows the rules or instructions mentioned by the developer, and performs its task accordingly.
Rule-based Chatbots are commonly used on websites to answer frequently asked questions (FAQs) or provide basic customer support.
2. Learning Based Approach
A learning-based approach is a method where a computer learns how to do something by looking at
examples or getting feedback, similar to how we learn from experience. Instead of being explicitly
programmed for a task, the computer learns to perform it by analyzing data and finding patterns or rules
on its own.
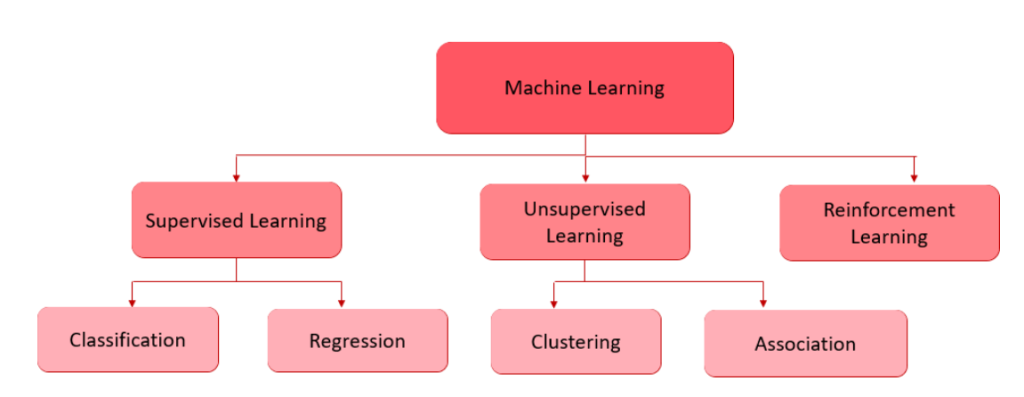
(a) Supervised Learning
In a supervised learning model, the dataset which is fed to the machine is labelled. In other
words, we can say that the dataset is known to the person who is training the machine only
then he/she is able to label the data. A label is some information which can be used as a tag
for data. For example, students get grades according to the marks they secure in
examinations. These grades are labels which categorize the students according to their marks.
(i) Classification Model
Here the data is classified according to the labels. For example, in the grading system, students are classified on the basis of the grades they obtain with respect to their marks in the examination. This model
works on discrete dataset which means the data need not be continuous. For eg. Classifying emails as spam or not.
(ii) Regression Model
Regression: Such models work on continuous data. For example, if you wish to predict your next salary, then you would put in the data of your previous salary, any increments, etc., and would train the model. Here, the data which has been fed to the machine is continuous. Regression algorithms predict a continuous value based on the input variables. For eg. Predicting temperature, Predicting the price of the house, Used Car Price Prediction etc
(b) Unsupervised Learning
An unsupervised learning model works on unlabelled dataset. This means that the data which is fed to the
machine is random and there is a possibility that the person who is training the model does not have any
information regarding it. The unsupervised learning models are used to identify relationships, patterns and trends out of the data which is fed into it. It helps theuser in understanding what the data is about and whatare the major features identified by the machine in it.
(i) Clustering
Clustering is a process of dividing the data points into different groups or clusters based on their similarities between them. Clustering finds similarities between objects and places them in the same cluster and
it differentiates them from objects in other clusters.
(ii) Association
Association Rule is an unsupervised learning method that is used to find interesting
relationships between variables from the database
Example: Based on the purchase pattern of customers A and B, can you predict any Customer X who
buys bread will most probably buy?
Based on the purchase pattern of other customers, we can predict that there is highprobability
that any customer x who buys bread will most probably buy butter.
Therefore,such meaningful associations can be usefulto recommend itemsto customers. Thisis
called Association Rule.
(c) Reinforcement Learning
This learning approach enables the computer to make a series of decisions that maximize a reward metric for the task without human intervention and without being explicitly programmed to achieve the task.
Reinforcement learning is a type of learning in which a machine learns to perform a task through a repeated trial-and-error method.
Supervised Vs. Unsupervised Learning
| Supervised Learning | Unsupervised Learning |
| • Deals with labelled data | • Deals with unlabelled data |
| • Useful in real-world problems-like predicting the prices of an item something based on past trends. | • Useful in finding unknown patterns within data-like making sense of a large number of observations from an experimental device. |
| • Simpler computing power is required as clean labelled data is used as input. | • More complex computing power is required as unsorted and messy data is used as input. |
Classification VS Clustering
While both are foundational techniques in machine learning, the primary difference lies in whether you are using a “map” (predefined labels) or “exploring” (finding patterns on your own).
In Classification, you are asking the machine to recognize something you already know. In Clustering, you are asking the machine to tell you something you didn’t know about how your data is organized.
| Feature | Classification (Supervised) | Clustering (Unsupervised) |
| Data Requirement | Requires Labeled Data (the model knows the correct categories beforehand). | Uses Unlabeled Data (the model has no prior knowledge of categories). |
| Process | Assigns objects into predefined classes. | Finds similarities between objects to create new groups. |
| Nature of Task | Predictive: It maps a new input to a known category. | Descriptive: It discovers the underlying structure of the data. |
| Goal | Accuracy: How well did it predict the correct label? | Discovery: How distinct and meaningful are the groups? |
| Real world application | (i) Medical diagnosis (Healthy vs. Diseased). (ii) Image recognition (Identifying a cat vs. a dog). (iii) Credit scoring (High risk vs. Low risk). | (i) Market segmentation (Grouping customers by similar buying habits). (ii) Document analysis (Grouping news articles by topic). (iii) Genetics (Grouping similar DNA sequences). |
| Key Differences | Predefined: You start with categories like “Spam” and “Not Spam.” The model learns the features of each and sorts new emails into those two buckets. | Discovered Groups: You provide a million emails with no labels. The model might group them into “Work,” “Newsletters,” and “Personal” based on word frequency, without you ever telling it those categories exist. |
Ques: Differentiate AI, ML, and DL. Also draw a labelled Venn Diagram depicting the relationship between them.
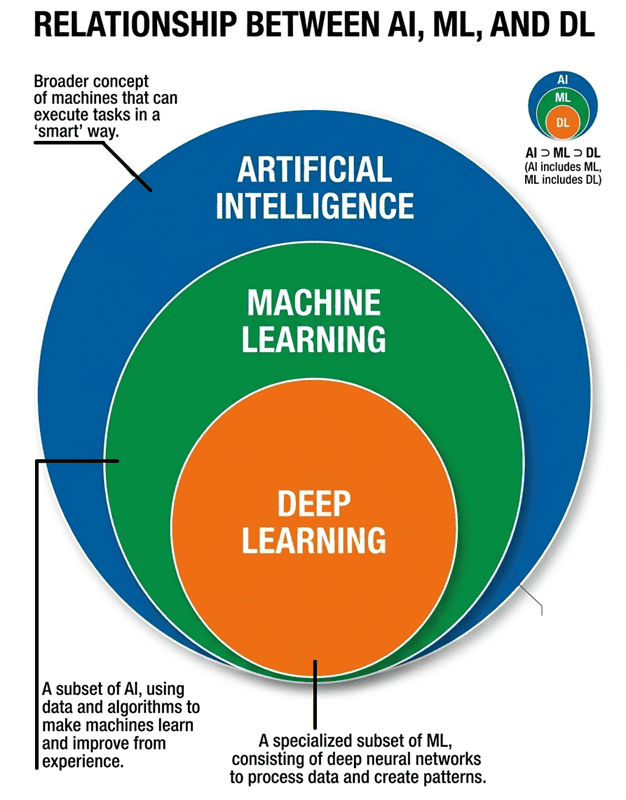
- Artificial Intelligence (AI): AI refers to the development of computer systems capable of performing tasks that typically require human intelligence and decision-making.
- Machine Learning (ML): A subset of AI that uses algorithms to learn from data and improve through experience without being explicitly programmed for every task.
- Deep Learning (DL): A specialized subset of ML based on artificial neural networks (inspired by the human brain) to solve highly complex problems using large amounts of data.
Ques: Explain Train-test split technique.
The train-test split is a fundamental AI model evaluation/validation technique in machine learning that divides a dataset into two subsets: one for training the AI model and one for testing its performance. This process simulates how a model will perform on unseen data.
Training Set: This portion, typically comprising 70-80% of the total data, is used to train the model. The algorithm learns the underlying patterns and relationships within this data.
Testing Set: The remaining 20-30% of the data is held back and used as a “final exam” for the model. Because the model has never seen this specific data during its training phase, its performance here provides an unbiased estimate of how it will behave in the real world.